At the end of my long post yesterday on the Reserve Bank’s latest efforts to spin the Governor’s plans to increase very markedly minimum capital ratios for locally-incorporated banks, I noted
PS. As Martien Lubberink at Victoria has pointed out there is another international agency paper out just recently that really doesn’t help the Bank’s case much if at all. I might touch on that tomorrow.
His post is here (complete with the sly – if obscure, presumably deliberately so – dig at the Governor in the final paragraph).
The paper he was referring was recently published by the Bank for International Settlements as a Working Paper of the Basel Committee on Banking Supervision, with the title “The costs and benefits of bank capital – a review of the literature”. The paper was released only a couple of weeks ago, and it should be studied carefully by anyone interested in the issues here in New Zealand, including (one hopes) the Reserve Bank.
The paper begins
In 2010, the Basel Committee on Banking Supervision published an assessment of the long-term economic impact (LEI) of stronger capital and liquidity requirements (BCBS (2010)). This paper considers this assessment in light of estimates from later studies of the macroeconomic benefits and costs of higher capital requirements.
That earlier paper is referenced everywhere the issues are discussed, including in the Reserve Bank’s papers earlier in the decade, and in its consultative document for this review. It supported – to some extent made – the (macro) case for higher capital ratios, in particular higher than had been in place up to that point (shortly after the crisis). A review and update of the issues, by a group involving officials from the BIS, the Bank of England, the Banque de France, the Fed and Comptroller of Currency (among others) has to be taken seriously, including when the authors highlight the limitations of their own work, and outline areas needing further research. The paper looks at many of the same studies the Reserve Bank cites but – in Lubberink’s words –
The conclusions of the Basel Committee study, however, are different. They are much more modest than the findings of the RBNZ.
Before going on, I should say that I have serious problems with elements of the approach taken in the earlier and more recent BCBS papers (various points outlined at greater length in my own submission). In particular, this work (and the Reserve Bank) treats all output losses in recessions associated with financial crises as being attributable to the financial crisis (bank failures etc) itself. That is almost certainly wrong, and substantially overestimates the cost of crises themselves – the loan losses that lead to bank failures arise from misallocations of investment resources (and/or overheated economies) and those misallocations will be corrected anyway (with likely output costs), whether or not any bank fails. Remarkably – and this is clearer in the more recent paper – they also treat output losses in countries that didn’t have domestic financial crises (think Australia or Canada in 2008/09) as costs of financial crises, rather than allowing for the more plausible story that common third factors will have been driving, say, productivity growth slowdowns across the advanced world. As I’ve argued (and as Cline, in a PIIE paper a few years ago, also made the case), if you want to isolate the output costs of financial crises, a better way is to look at the differential growth performance between (otherwise similar) countries that did and did not experience domestic financial crises.
A great deal turns – in these sorts of modelling exercises – on how costly the modellers assume crises will be. Both my points in the previous paragraph suggest the BCBS conclusions – as to how much capital is likely to be warranted – are likely to materially overstate the “true” numbers.
There are all sorts of other limitations to the BCBS work. For example, it focuses on “banks”, but doesn’t address the fact that for an individual country – think New Zealand – a capital requirement on locally-incorporated banks won’t affect branches of foreign banks operating locally, or non-bank lenders. Disintermediaton costs don’t figure. It also, more generally, won’t apply to debt capital market funding. Unlike the Reserve Bank, the BCBS paper does touch on the issue of alternative resolution mechanisms – the Bank long favoured the OBR approach, but it was never mentioned in the consultative document, even though the more confident you are of OBR (I’m not, but they were) the less capital is required – but it doesn’t touch on the issue of a banking system in which the large banks all have strong foreign parents. And it doesn’t take account – in the macro calculations – of the possible income losses to New Zealanders from the higher equity returns to foreign shareholders (much of the overseas modelling seems assume redistribution of income within the country). This latter point, in particular, has been covered in Ian Harrison’s papers.
On my reading, this is the bottom line chart in the BCBS paper.
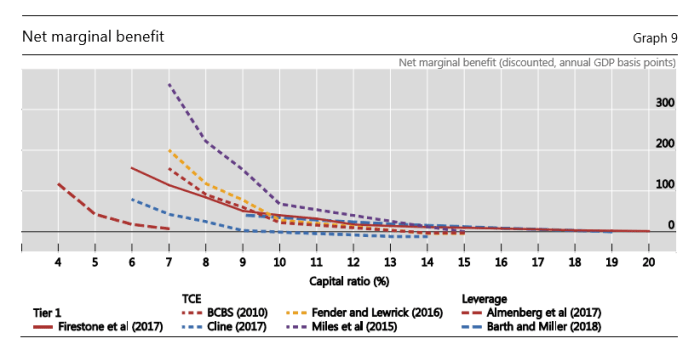
They report the net marginal economic benefit (slightly lower GDP each year, offset against savings from a less serious crisis decades hence) from higher bank capital ratios, drawn from a series of studies. On these models there were really big gains in lifting capital ratios, up to around to around 9-10 per cent. If there are gains at all – and they don’t report margins of error around these estimates – they are looking extremely small beyond about 13 per cent. Perhaps that doesn’t sound too far from the 16 per cent number the Reserve Bank is proposing for the big banks but (among other limitations, many made inevitable by data limitations):
- this modelling is done on actual capital ratios, not regulatory minima (a 16 per cent minimum ratio is likely to see banks aim for something between 17 and 18 per cent actual ratio), and
- none of this modelling takes account of differences in accounting and regulatory treatment across countries: conventional wisdom, (backed by estimates done by PWC) suggest that effective capital ratios in New Zealand (and Australia) would be far higher if things were measured the same way they were done in various other advanced countries, and
- none of it takes account of the regulatory floor in how risk-weighted assets are calculated. As the Bank is quite open about, a significant part of what is proposing is that in calculating risk-weighted assets, the big banks will have a floor of 90 per cent of what the standardised rules would generate (the more normal floor is, as I understand it, about 72 per cent). A 17.5 per cent headline actual capital ratio would, on RB proposed rules, be akin to something like 20 per cent in the sort of framework the BCBS authors are looking at.
Nothing in this paper suggests any reason for confidence that effective capital ratios of, say, 20 per cent of risk-weighted assets would be generating net economic benefits, even on the (overly pessimistic) macro assumptions the authors are using. But that is what the Reserve Bank claims to believe. The onus, surely, is on them to show us, and to engage on their assumptions and analysis – in open dialogue – well before decisions are made.
And then lets go back to the macroeconomic inputs. If most of the costs of recessions associated with financial crises would have happened anyway (see above) then the output losses used in these models are substantially overstated. Higher capital ratios make no difference to whether those losses occur. Cline (the lower blue line in the chart) uses assumptions more similar to mine: you can see where the crossover point (to net costs) is for him.
Note too that real interest rates and the real cost of capital are higher in New Zealand than in most advanced countries. The median (real) discount rate used in the studies the BCBS paper looks at is something like 3.5 per cent and none uses a real rate higher than 5 per cent. A standard New Zealand Treasury guidance for cost-benefit analyses on regulatory proposals is (real) 6 per cent. Using a higher discount rate materially reduces any benefits from a crisis assumed to arise, probabilistically, decades in the future. And yet even on the studies reviewed by the BCBS, there is no consensus in favour of anything near as high as the effective capital ratios the Governor is proposing.
And, as I’ve pointed out previously, all this work implicitly assumes that any higher capital ratios can be made binding for decades to come. Since there is no pre-commitment technology, and actual rules have been changed every few years, there should be a further discounting of any potential gains, particularly in light of the inevitable transition costs from big increases in capital requirements (which are frontloaded, and represents permanent losses, for what may be a temporary policy).
It was also interesting to be reminded, in an annex, of this feature of the earlier (LEI) BCBS modelling
The main results of the LEI appear in Table 8, p 29, of BCBS (2010). The calibration used is the following:
• the probability of a crisis is 4.6% for a capital ratio of 7%, and declines at a diminishing rate to 0.3% for a capital ratio of 15%.
In other words, a probability of a crisis every 333 years with an (actual) capital ratio – calculated as more conventionally abroad – of 15 per cent. And yet the Reserve Bank’s proposals were supposed to be calibrated to a crisis every 200 years, and yet still somehow generate effective capital ratios of 18 per cent plus for the big banks.
Now in many respects Martien Lubberink’s comment is fair, that for all sorts of reasons
studies on bank capital are more quicksand than a sound foundation for policy recommendations.
And yet, they have been repeatedly invoked by the Reserve Bank, and – when read carefully – do still provide a commonsense test against which the benchmark the Governor’s ill-considered far-reaching proposals for New Zealand.
The whole exercise really should be suspended. Come back to it perhaps in a few years’ time when a revised Reserve Bank Act is in place, and when there has been proper parliamentary and public scrutiny of the assignment of powers to the Reserve Bank (which policymaking powers should rest with ministers and which with agencies). And use the intervening period to undertake some serious local research, working collaboratively with APRA (recognising the common risks, common ownership, likely common resolution) and engaging in workshops and seminars to tests the strengths and weaknesses of staff thinking and research well before decisionmaking authorities reach a provisional view.
And, in meantime, take comfort from the fact that before the IMF suddenly swung in behind the Governor, when there were no institutional pressures at play that international agency only a year ago told us, and told the world, that there were ample capital buffers in the New Zealand banking system.

The risks haven’t changed materially in that time, it is just that the gubernatorial whim has since been revealed. Such whims are a terrible basis for making serious policy, especially when there are no checks, no appeals, on the Governor’s ability to impose such substantial transitional and ongoing costs on New Zealanders.
,
